Even without directly hearing sounds, humans can effortlessly reason about auditory properties, such as pitch, loudness, or sound-source associations, drawing on auditory commonsense. In contrast, language models often lack this capability, limiting their effectiveness in multimodal interactions. As an initial step to address this gap, we present AuditoryBench++, a comprehensive benchmark for evaluating auditory knowledge and reasoning in text-only settings. The benchmark encompasses tasks that range from basic auditory comparisons to contextually grounded reasoning, enabling fine-grained analysis of how models process and integrate auditory concepts. In addition, we introduce AIR-CoT, a novel auditory imagination reasoning method that generates and integrates auditory information during inference through span detection with special tokens and knowledge injection. Extensive experiments with recent LLMs and Multimodal LLMs demonstrate that AIR-CoT generally outperforms both the off-the-shelf models and those augmented with auditory knowledge.Experiments demonstrate that AIR-CoT outperforms off-the-shelf and augmented models. We believe our work provides a strong foundation for building language models that can imagine auditory information without direct audio input, ultimately enabling more natural and human-like multimodal reasoning.
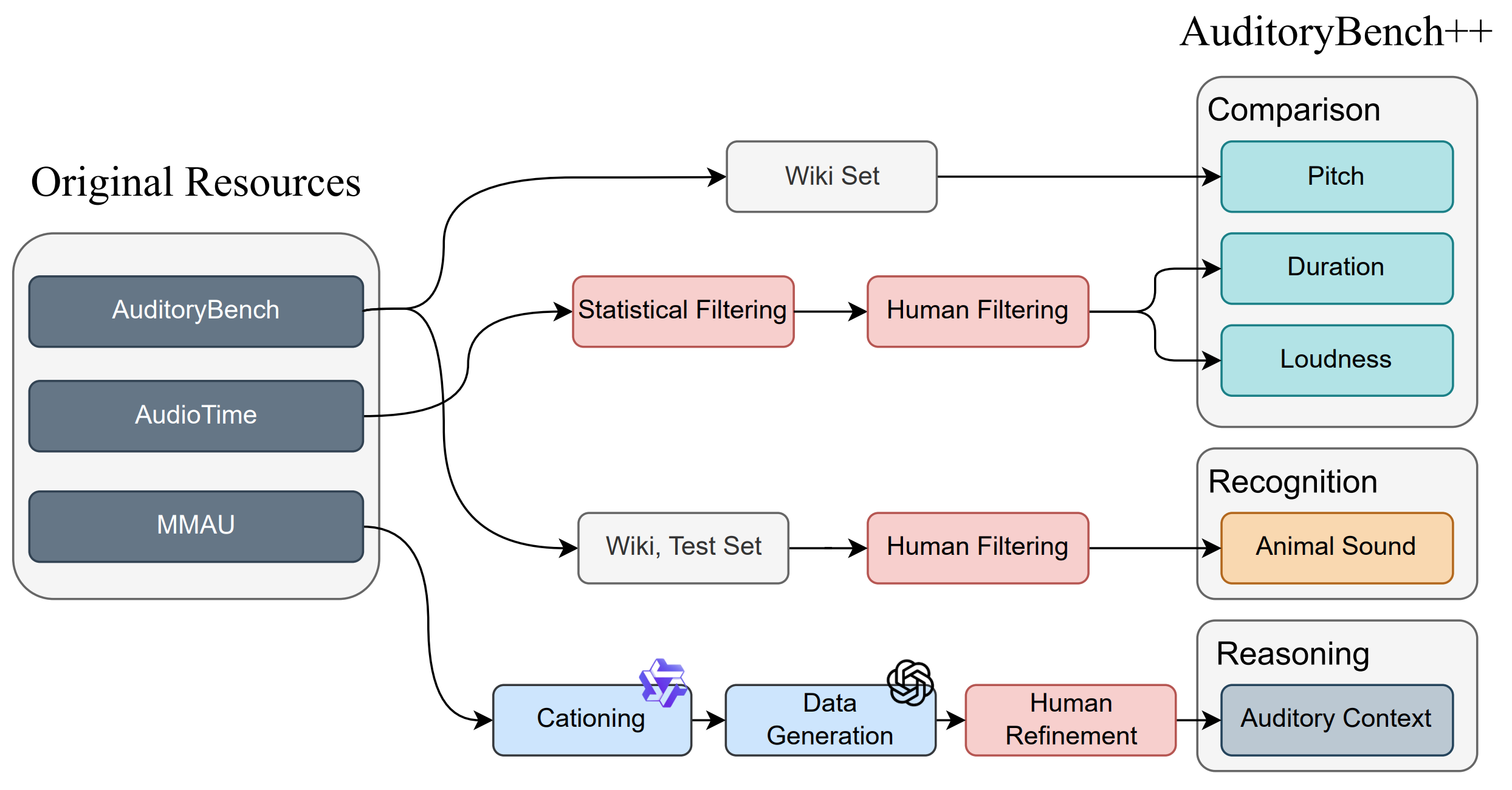
The construction pipeline is presented below, with tasks grouped by their original resource.
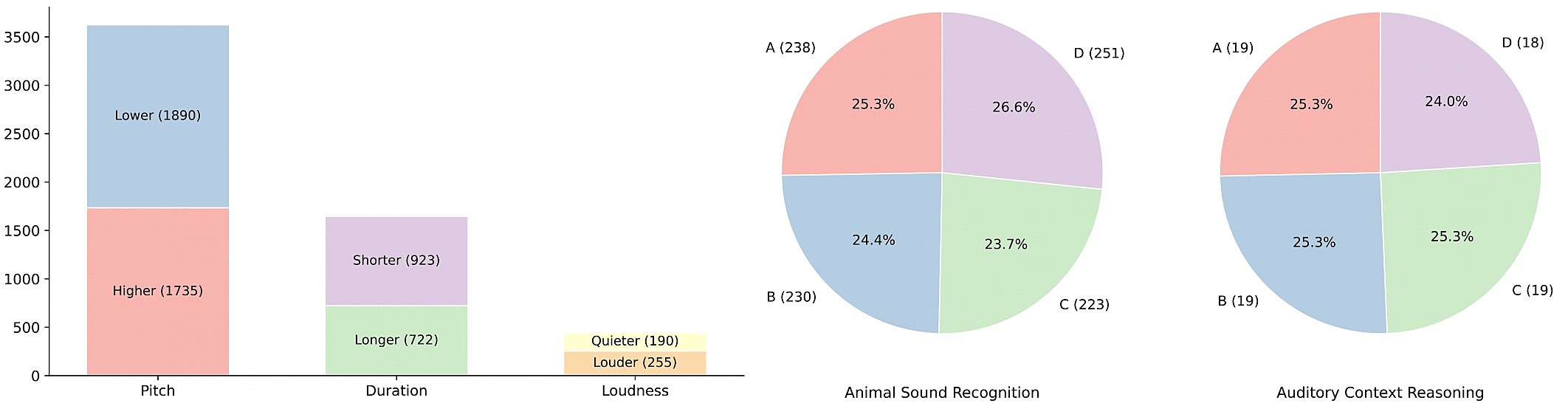
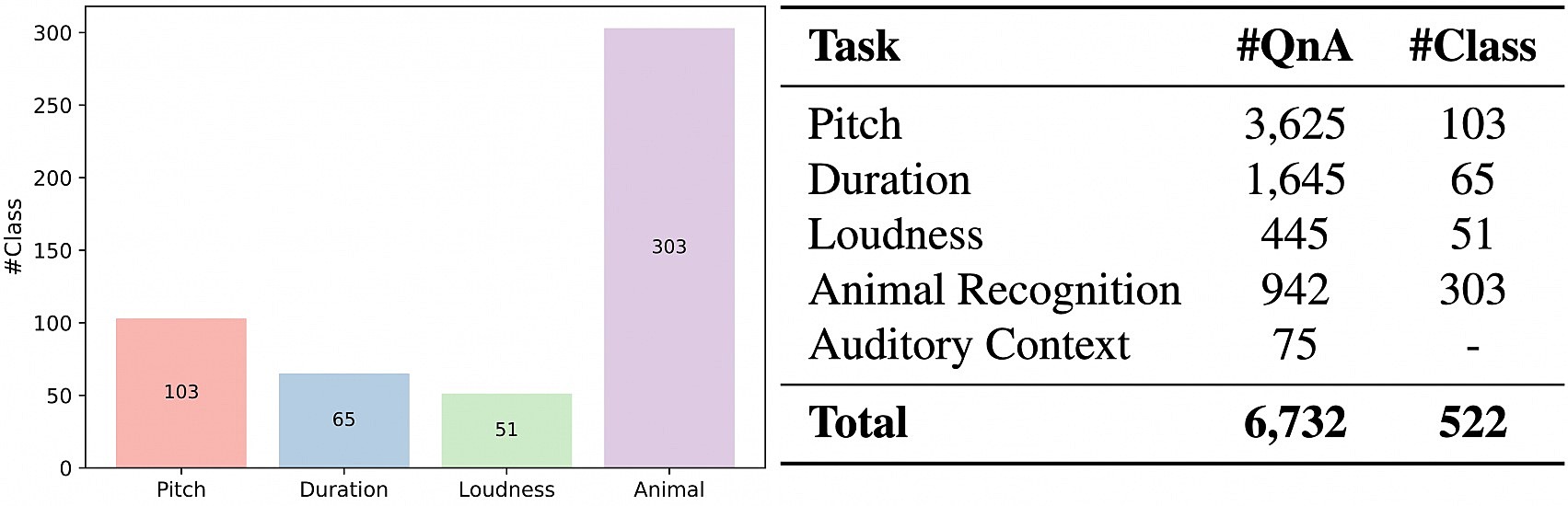
AuditoryBench++ comprises 5 tasks evaluating a spectrum of auditory knowledge, from fundamental comparisons to complex, contextually grounded reasoning:
The sound of Bass is [MASK] than the sound of Alto.
The sound of Cello is [MASK] than the sound of Violin.
The sound of Harp is [MASK] than the sound of bass saxophone.
The sound of flute is [MASK] than the sound of bass trumpet.
The sound of clicking is [MASK] than the sound of aircraft engine.
The sound of quack is [MASK] than the sound of alarm clock.
The sound of meow is [MASK] than the sound of ambulance (siren).
The sound of oink is [MASK] than the sound of vehicle horn.
The sound of applause is [MASK] than the sound of knock.
The sound of baby cry, infant cry is [MASK] than the sound of sigh.
The sound of tick is [MASK] than the sound of cough.
The sound of drill is [MASK] than the sound of printer.
[MASK] make a chirp sound.
The sound of buzzing is usually associated with a [MASK].
The sound of [MASK] chewing grass is a common farm sound.
At night, in the summer, you can hear the [MASK] chirping.
What type of natural sound is described as water splashing continuously?
Where is the sound of someone snoring most likely coming from?
During a street busking performance with bells and a xylophone, what background noise is most likely heard?
What musical genre is described as a piece with a positive vibe suitable for a road trip scene?
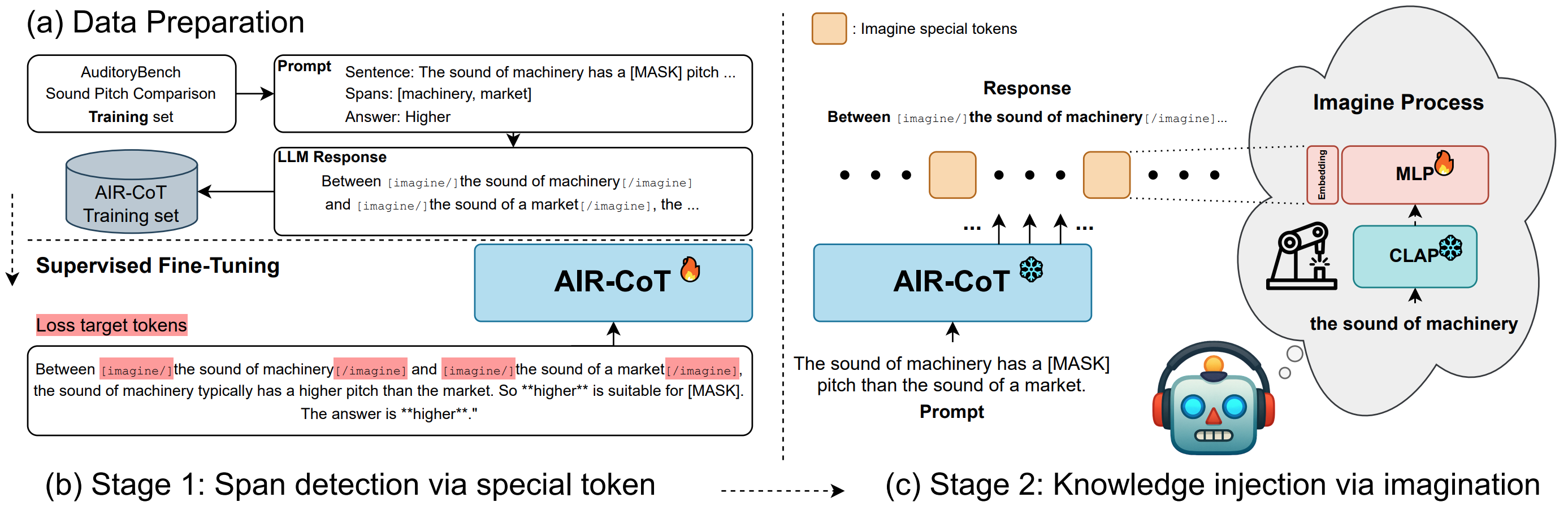
Pipeline of the proposed AIR-CoT:
@article{ok2025auditorybench++,
title={AuditoryBench++: Can Language Models Understand Auditory Knowledge without Hearing?},
author={Ok, Hyunjong and Yoo, Suho and Kim, Hyeonjun and Lee, Jaeho},
journal={arXiv preprint arXiv:2509.17641},
year={2025}
}